Announcing the CloudQuery Snowflake Destination Plugin
November 24, 2022

- Name
- Yevgeny Pats
- @yevgenypats
Introduction
Cloud infrastructure data exploded over the last decade. Some teams using CloudQuery open source now collect data on more than 50 million (!) of their organization's cloud resources on a daily basis. This explosion has created the need to store this data in data warehouses and data lakes for better scalability, analysis and reporting. Today I'm excited to announce the release of our new Snowflake destination plugin, which enables you to achieve this by syncing all supported CloudQuery source plugins directly to a Snowflake database.
Use Cases
Cloud Infrastructure data lake and data warehouse
Snowflake is already used as a "Security data lake". CloudQuery brings all your cloud infrastructure configuration data to the same place, consolidating your security and infrastructure data in one place and enabling new insights.
Historical data
Maintaining historical data is a common use case for data warehouses. By using Snowflake as a destination, you can now store all your cloud infrastructure data in a data warehouse for long term storage, analysis and investigation use-cases.
Syncing data
Syncing data to snowflake can be done as with any other destination plugin, so check out our Quickstart and Snowflake plugin documentation.
There are two ways to sync data to Snowflake:
-
Direct (easy but not recommended for production or large data sets): This is the default mode of operation where the CQ plugin will stream the results directly to the Snowflake database. There is no additional setup needed apart from authentication to Snowflake.
-
Loading via CSV/JSON from a remote storage: This is the standard way of loading data into Snowflake, it is recommended for production and large data sets. This mode requires a remote storage (e.g. S3, GCS, Azure Blob Storage) and a Snowflake stage to be created. The CQ plugin will stream the results to the remote storage. You can then load those files via a cronjob or via SnowPipe. This method is still in the works and will be updated soon with a guide.
Once data is synced you can start querying either with the native Snowflake interface, code or with any BI tool that supports Snowflake. Here is the "Hello World" of cloud infrastructure queries:

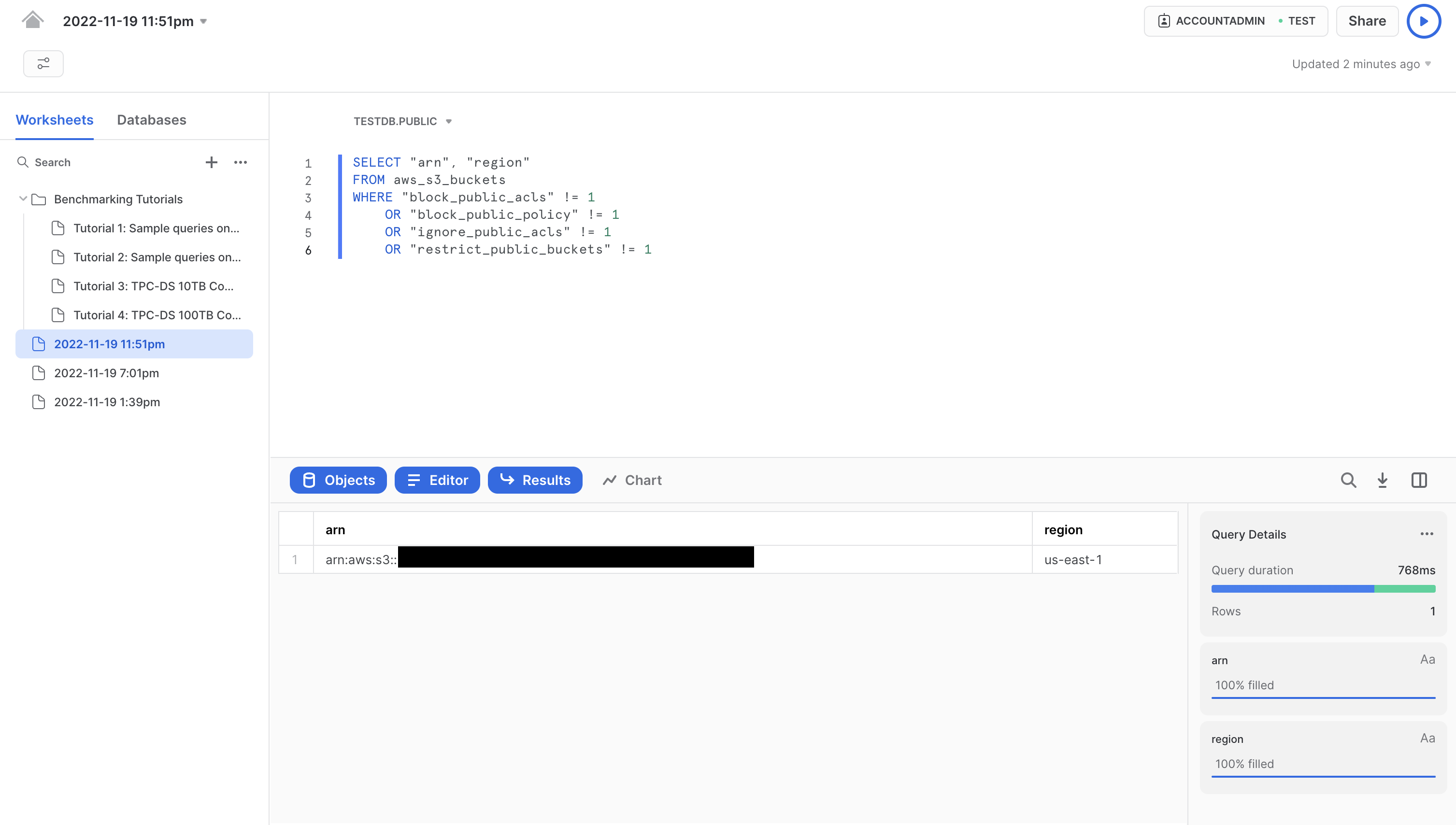
Summary
This is the first Snowflake destination plugin release. More improvements are coming, and I'd love to hear your use-cases and ideas on how to leverage it. Feel free to open an issue on GitHub or join our Discord to share your ideas.
